Node의 특징
Node란 서로의 메모리 주소를 참조하는 형태로 이루어진 자료구조이다.
Node는 인덱스를 통해 추가 및 삭제 시 위치를 O(n)으로 찾지만, 찾은 이후에는 일부 Node의 참조값만 변경하면 되므로 해당 부분이 O(1)로 빠르다.
- 앞에 추가하는 경우 : 연결리스트는 배열리스트 처럼 추가한 항목의 오른쪽에 있는데이터를 밀지 않고 참조값만 변경하면 되므로 데이터를 앞쪽에서 추가하는 경우 연결리스트가 보통 더 좋은 성능을 제공한다
- 마지막에 데이터를 추가하는 경우 : 노드를 마지막까지 순회해야 마지막 노드를 찾을 수 있다. 따라서 마지막 노드를 찾는데 O(n)의 시간걸린다, 데이터를 추가하는 경우 일부 노드의 참조만 변경하면 된다. O(1), 따라서 O(n)의 성능을 제공한다.
ArrayList와의 차이점
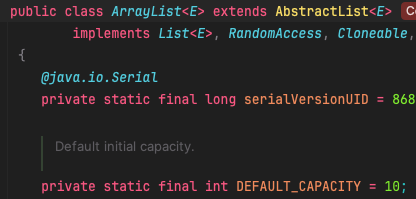
ArrayList는 처음에 10이라는 공간을 가지고 생성되는데, 배열의 사용되지 않는 공간이 낭비되는 단점이 있다.
배열은 필요한 배열의 크기를 미리 확보해야한다. 데이터가 얼마나 추가될지 예측할 수 없는 경우 나머지 공간은 사용되지 않고 낭비되는 것이다.

그렇다면 낭비되는 메모리 없이 딱 필요한 만큼만 메모리를 확보해서 사용하고, 또 앞이나 중간에 데이터를 추가 및 삭제할 경우에도 효율적인 자료구조가 존재하는데, 바로 Node이다. Node는 Node를 만들고 각 Node를 서로 연결하는 방식이다.

package collection.link;
public class MyLinkedList {
private Node first;
private int size = 0;
//코드 추가 addIndex public void add(int index, Object e) {
Node newNode = new Node(e);
//맨 앞에다가 데이터 추가시
if (index == 0) {
// newNode가 자신이 들어오기전의 첫번째 노드를 가리키도록 함
newNode.next = first;
// 첫번째 노드가 newNode가 되도록 하는 것. first는 해당 클래스의 필드이다.
first = newNode;
} else {
Node prev = getNode(index - 1);
newNode.next = prev.next;
prev.next = newNode;
}
size++;
}
// 코드 추가 remove 기존값을 반환해주기 위해서 Object 반환
public Object remove(int index) {
Node removeNode = getNode(index);
Object removedItem = removeNode.item;
//삭제할 노드 위치가 맨 앞일경우
if (index == 0) {
// first -> newNode
first = removeNode.next;
} else {
Node prev = getNode(index - 1);
prev.next = removeNode.next;
}
//연결을 끊어주기 위해 null을 넣어준다. -> GC가 처리
removeNode.next = null;
removeNode.item = null;
size--;
return removedItem;
}
```
**Object get(int index)**
특정 위치에 있는 데이터를 반환한다.
- O(n)
- 배열은 인덱스만 알고있다면 원하는 즉시 해당 인덱스를 찾아가서 값을 찾아 꺼내올수있다O(1), 하지만 `LinkedList`에서의 get()은 해당 노드까지 반복해서 찾아야한다. 따라서 인덱스 조회 성능이 배열에 비해서 좋지 않다.
- 단지 다음 노드에 대한 참조값만 갖고있을 뿐이다.
- 특정 위치의 노드를 찾는데 O(n)이 걸린다.
**void add(Object e)**
마지막에 데이터를 추가한다.
- O(n)
- 마지막 노드를 찾는데 O(n)이 소요된다. 데이터를 추가할 때도 마지막 노드까지 이동한 뒤에 그 다음의 next가 null일 경우 값을 추가하기 때문이다. 마지막 노드에 값을 추가하는데는 O(1)이 걸리지만, 전체적인 add() 메서드의 성능은 O(n)이다.
**Object set(int index, Object element)**
특정 위치에 있는 데이터를 찾아서 변경한다. 그리고 기존 값을 반환한다.
- O(n) -> 특정 위치의 노드를 찾는데 걸린다.
**int indexOf(Object o)**
데이터를 검색하고 검색된 위치를 반환한다.
- O(n) -> 모든 노드를 순회하면서 인자로 들어온 값을 찾기 때문이다 `equals()`를 사용해서 같은 데이터가 있는지 찾는다.
Node를 통해 데이터를 추가하는 방식은 꼭 필요한 메모리만 사용된다. 배열의 단점인 메모리 낭비를 해결할 수 있었다.
**물론 연결을 유지하기 위한 추가 메모리가 사용되는 단점은 존재한다(next에서 다음 참조를 알아야 되기 때문에).**
**실행**
```java
public class MyLinkedListV2Main {
public static void main(String[] args) {
MyLinkedListV2 list = new MyLinkedListV2();
//데이터가 마지막에 추가 되기 때문에 O(n)
list.add("a");
list.add("b");
list.add("c");
System.out.println("list = " + list);
// 첫번째 인덱스에 데이터 추가 -> O(1)
System.out.println("첫번째 인덱스에 데이터 추가");
list.add(0,"d");
System.out.println("list = " + list);
// 첫번째 인덱스에 데이터 삭제 -> O(1)
System.out.println("첫번째 인덱스에 데이터 삭제");
list.remove(0);
System.out.println("list = " + list);
// 첫번째를 제외한 특정 인덱스에 데이터 추가 -> O(n)
System.out.println("특정 인덱스에 데이터 추가");
list.add(3,"e");
System.out.println("list = " + list);
// 첫번째를 제외한 특정 인덱스에 데이터 삭제 -> O(n)
System.out.println("특정 인덱스에 데이터 삭제");
Object remove = list.remove(2);
System.out.println(remove);
System.out.println("list = " + list);
}
}
```직접 만든 배열리스트와 연결리스트의 성능 차이
| 기능 | 배열리스트 | 연결리스트 |
|---|---|---|
| 인덱스 조회 | O(1) | O(n) |
| 검색 | O(n) | O(n) |
| 앞에 추가 및 삭제 | O(n) | O(1) |
| 뒤에 추가 및 삭제 | O(1) | O(n) |
| 평균 추가 및 삭제 | O(n) | O(n) |
인덱스 조회 -> 배열리스트 O(1), 연결리스트 O(n)
앞에 추가 및 삭제 -> 배열리스트 O(n), 연결리스트 O(1)
뒤에 추가 및 삭제 -> 배열리스트 O(1), 연결리스트 O(n)
각 상황에 O(n)인 이유
인덱스로 조회시 연결리스트는 해당 인덱스까지 노드를 쭉 쫓아가야 한다.
앞에 추가 및 삭제시 배열리스트는 나머지 데이터들을 뒤로 쭉 밀어야 한다.
뒤에 추가 및 삭제시 연결리스트는 맨 뒤의 노드까지 쭉 쫓아가야 한다.
배열 리스트 vs 연결 리스트 사용
데이터를 조회할 일이 많고, 뒷 부분에 데이터를 추가한다면 배열리스트가 더 좋은 성능을 제공한다.
앞쪽의 데이터를 추가하거나 삭제할 일이 많다면 연결리스트를 사용하는 것이 더 좋은 성능을 제공한다
'Java > Collection' 카테고리의 다른 글
| [Collection] Java의 Map (0) | 2024.05.29 |
|---|---|
| [Collection] Java의 Set과 hashCode() (0) | 2024.05.29 |
| [Collection] Java의 TreeSet의 특징 및 구조 (0) | 2024.05.29 |
| [Collection] 자바의List 그리고 ArrayList,LinkedList 실제 성능 테스트 (0) | 2024.05.24 |
| [Collection] Java의 배열과, ArrayList (0) | 2024.05.24 |